Configuration de l'indexation plein texte
L'opérateur du système d'archivage configure l'indexation plein texte en adaptant des valeurs de directives de configuration. Deux possibilités d'extraction plein texte sont proposées, soit de l'extraction basée sur des fichiers texte (par exemple des pdf, des documents bureautiques, etc..), ou basée sur des images (png, jpeg, etc).
Le choix du type d'extraction et des fichiers à prendre à compte en fonction se base sur le puid (PRONOM Unique IDentifier, voir: Liste des formats) des fichiers.
- Le logiciel Apache Tika est utilisé pour l'extraction de texte de fichier de type texte, il est récupérable ici, prendre la version .jar et renseigner son chemin dans la directive de configuration tikaJarExecutable
- Le logiciel tesseract est utilisé pour l'extraction de texte issue d'image (disponible ici). Si l'installation n'est pas faite de manière globale, le chemin vers l'executable est à renseigner dans la directive de configuration tesseractExecutable
Une fois ce (ou ces) programmes installés, il faut encore paramétrer la directive fullTextServices qui est un tableau de services se décomposant en 3 paramètres:
- serviceName : Nom du service à utiliser pour l'extraction
- inputFormat : liste de tous les puids pouvant être indexer par le ServiceName renseigné
- options : Options complémentaires pouvant être utiles à l'utilisation de fonctionnalités additionelles des utilitaires d'extraction (se référer à leur documentation)
Paramètrage de l'indexation
L'indexation plein texte se basant sur le puid des fichiers, il est nécessaire que la détection de formats soit validée dans les niveaux de service ainsi que l'indexation plein texte;
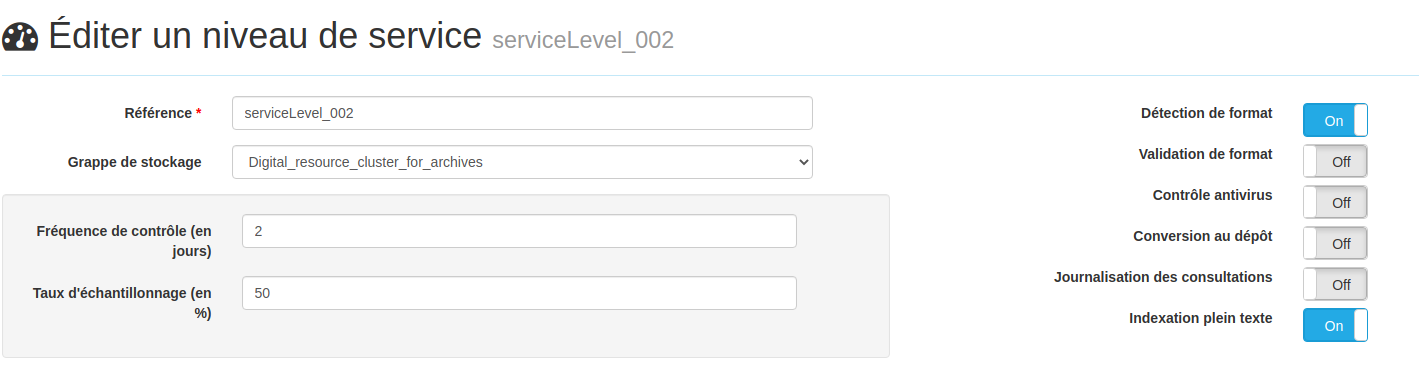
Dans le planificateur des tâches, il est possible de configurer l'indexation plein texte.
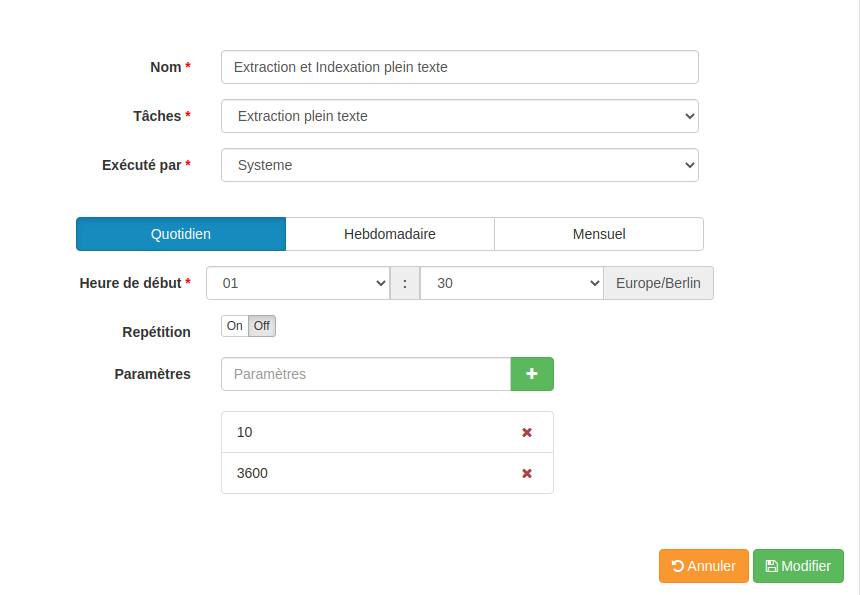
L'extraction dispose de deux paramètres configurable que sont le nombre limite d'archives à extraire et le temps maximum d'extraction. Si aucun paramètre n'est renseigné l'extraction se fera sans limite de temps ni de nombre. Néanmoins, cette opération pouvant être longue, il est laissé la possibilité à l'administrateur de limiter cette tâche.
En raison des limitations de l'écran du planificateur, il n'est pas pour l'instant possible de référencer les champs. Il est donc nécessaire de renseigner les deux champs si l'on veut uniquement renseigner le deuxième paramètre.
Le premier paramètre configurable est la limite du nombre d'archives à indexer. La valeur à renseigner est un entier (défaut null). Une fois le nombre d'archives renseignée atteint, l'indexation s'arrêtera et reprendra lors de la prochaine exécution de la tâche planifiée.
Le paramètre temps permet de déterminer une durée maximale du script (en secondes). Il permet d'éviter une trop longue éxécution du script, l'indexation pouvant être chronophage. Il est à noter que le script s'arrête uniquement une fois que l'archive en cours d'indexation est finalisée. Donc si la limite de temps est atteinte pendant l'indexation d'une archive, le script continuera le temps de terminer l'indexation en cours.
Exemple de configuration avec une limite de 10 archives et un temps maximum d'une heure (3600 s)
Mots vides
La directive "stopWordsFilePath" permet de définir le chemin d'un fichier de "mots vides" n'étant pas pris en compte dans l'indexation plein texte :
stopWordsFilePath = "%laabsDirectory%/data/maarchRM/stopwords/stopwords_fr.txt"